
北京时间2月24日,三家中国头部AI公司DeepSeek、月之暗面、MiniMax遭到了AI编程顶流模型Claude的母公司Anthropic“点名批评”。
Anthropic称,这些中国公司“用2.4万个‘马甲账号’进行了1600万次对话,目的是提取Claude的能力来训练自己的模型”,其还创造了一个词汇,称这是“工业规模蒸馏攻击”。
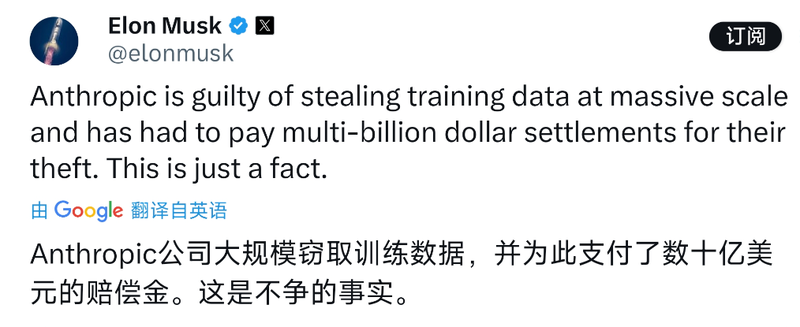
不过,这一指控随即遭到了埃隆·马斯克无情的“嘲讽”:“他们怎么敢偷Anthropic从人类程序员那里偷来的东西”“Anthropic公司大规模窃取训练数据,并为此支付了数十亿美元的赔偿金。这是不争的事实。”
另一方面,近年来国产模型能力不断提高,不少厂商已经将发展目标指向了Claude最引以为豪的编程能力。在被“点名”的同时,MiniMax、Kimi等国产模型的收入、调用量等指标已再创新高。中国AI公司正在用事实证明,技术封锁和空口指控无法阻挡国产AI的发展。
蒸馏也能成“攻击手段”?
蒸馏技术本无罪,问题在于谁在用、怎么用。
模型蒸馏是AI领域的标准训练技术,通过让大模型指导小模型学习,实现知识迁移和模型压缩。例如,DeepSeek在金融场景实践中将175B参数模型压缩至7B,推理成本降低98%的同时保持了95%以上核心指标;MiniMax的M2.5模型在SWE-bench Verified上达到80.2%,与Claude Opus 4.6的80.8%几乎持平,但成本仅为后者的1/20。
当前,蒸馏技术被全球AI公司普遍使用,包括OpenAI、谷歌、Meta等巨头都在自家模型上应用。事实上,就连Anthropic自己也在指控三家中国公司后,补充了一句“蒸馏法是合理的:人工智能实验室利用蒸馏为客户创建更小、更便宜的模型。”只不过,后面又跟上了一句“一些境外实验室非法提炼美国模型后,可移除其安全防护机制,将模型技术能力应用于本国的军事、情报及监控系统中。”
可以发现,Anthropic的逻辑是:蒸馏本身无罪,但当中国公司使用时,就成了“非法窃取”。
Anthropic声称,通过IP地址、请求元数据等信息将“攻击”追溯到了具体实验室,甚至以“与员工公开资料匹配”为由指向中国公司。但目前,这些指控仅为Anthropic的“一面之词”。
有声音认为,这样的溯源方式在法律层面难以成立,蒸馏技术迁移的是功能逻辑而非直接复制数据,更贴近法律允许的“反向工程”范畴。简单扣上“盗窃”帽子,并不能掩盖证据薄弱的事实。
这种指控也让人感觉是“贼喊捉贼”。Anthropic本身有过“窃取数据”的“黑历史”:2025年9月,Anthropic 因大规模从LibGen、PiLiMi等盗版网站非法下载超700万本受版权保护的图书,并使用这些盗版书籍训练AI模型,被迫向以作家安德里亚・巴茨(Andrea Bartz)为首的全球作家集体支付了15亿美元和解金。正如马斯克所说,“这是不争的事实。”
当前,AI行业尚处于规则空白期,蒸馏技术的边界在哪里、数据使用的底线是什么,需要全球共同制定标准。商业竞争无可厚非,但动辄扣帽子、搞双重标准,只会阻碍技术创新与普惠。当OpenAI、谷歌、Anthropic自己都在大规模使用未经许可的数据训练模型时,他们对“蒸馏”的指控,更像是维护既得利益的防御性反应。
不惧指责,中国AI模型奋起直追
对于Anthropic的单方面指责,月之暗面和MiniMax均未予以回应,其用意很明显:用数据和事实说话。
DeepSeek自2026年以来发表了多篇论文,并一以贯之地开源其最新研究成果,将“降本增效”贯彻到底。同时,DeepSeek也正在对新模型进行灰度测试,V4“呼之欲出”。
月之暗面方面向贝壳财经记者透露,在完成上一轮5亿美元融资仅一个多月后,其将完成新一轮超7亿美元的融资并再次超募,本轮由阿里、腾讯、五源、九安等联合领投。新一轮100亿—120亿美元估值的融资已经开启,并已收到多家机构意向。连续两轮超12亿美元的融资,创下近一年来大模型行业的更高融资纪录。
此前字节估值突破百亿美元大关用时超4年,拼多多用时超3年,Kimi仅用两年多的时间就实现估值30多倍的增长。照此看来,Kimi有望创下国内公司从成立到估值超100亿美元的最快成长速度。
而在模型的调用量方面,月之暗面旗下的Kimi K2.5大模型发布不到一个月,其近20天累计收入已超过2025年全年总收入。根据OpenRouter,Kimi K2.5的调用量在OpenClaw的模型调用榜中排名之一。
MiniMax方面则向贝壳财经记者披露,春节前夕MiniMax 开源新一代模型 M2.5,发布12小时内登顶OpenRouter热度榜,一周内登顶调用量榜首,周调用量暴涨至3.07T tokens。OpenRouter 整体调用量也在同步攀升。官方随后确认,M2.5 带动了100K至1M 长文本区间的增量调用需求,而这个区间正是Agent工作流的典型消耗场景。
事实上,中国AI公司的快速进步,源于庞大的工程师群体、丰富的数据资源、完善的产业链,以及对开源开放路线的坚持。DeepSeek、Kimi、MiniMax在编程、多模态、Agent等领域的突破,是技术创新与场景深化的结果。
新京报贝壳财经记者 罗亦丹
编辑 岳彩周
校对 柳宝庆
