炒股就看金麒麟分析师研报,权威,专业,及时,全面,助您挖掘潜力主题机会!
来源:人工智能顾问
日前,国内权威大模型评测机构SuperCLUE正式发布《2025年年度中文大模型基准测评报告》。这份被誉为“AI界年终成绩单”的重磅榜单,再次点燃了行业关注。
在全球23个顶尖大模型的激烈角逐中,海外巨头Anthropic、谷歌、OpenAI依旧稳居综合能力前三甲,但国产模型已不再“陪跑”——以Kimi-K2.5-Thinking与Qwen3-Max-Thinking为代表的中国力量强势突围,不仅在综合排名中紧随其后,更在代码生成与数学推理两大“硬科技”赛道中摘得全球桂冠。
这标志着国产大模型正从“追赶者”迈向“并行者”,甚至在特定领域实现“领跑”。
01 海外闭源模型领跑,国产模型紧咬不放
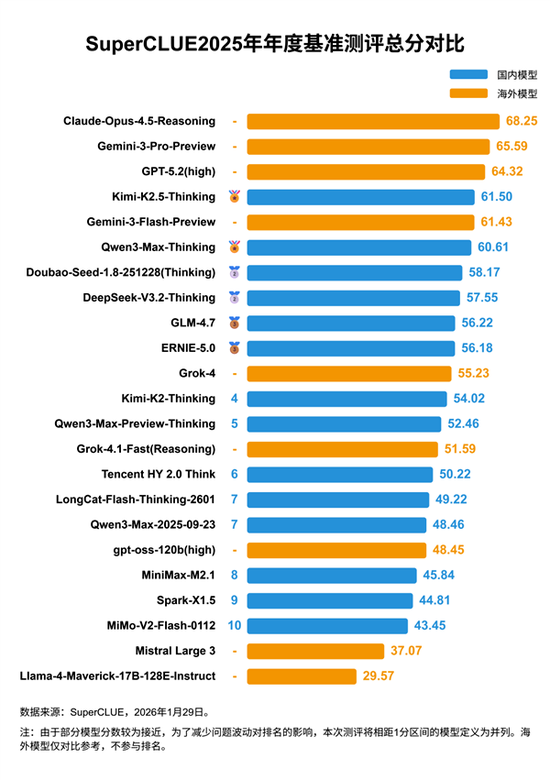
本次测评从数学推理、科学理解、代码生成等六大核心维度,全面检验大模型的综合智能水平。最终综合得分排名中:
●第1名:Claude-Opus-4.5-Reasoning(Anthropic)—68.25分
●第2名:Gemini-3-Pro-Preview(谷歌)—65.59分
●第3名:GPT-5.2(high)(OpenAI)—64.32分
三大海外闭源模型凭借其强大的工程优化与数据积累,继续领跑全球。
但值得注意的是,第4名由国产开源模型Kimi-K2.5-Thinking以61.50分强势拿下,成为综合排名更高的国产模型;而阿里云推出的高性能模型Qwen3-Max-Thinking则以60.61分位列第6,紧随其后,展现出中国头部AI企业的双线作战能力。
02 单项登顶:国产模型实现“局部反超”
如果说综合排名仍显差距,那么在细分赛道上,国产模型已实现历史性突破:
●代码生成单项赛:Kimi-K2.5-Thinking以53.33分高居榜首,超越GPT-5.2与Gemini-3-Pro,成为本次测评中代码生成能力最强的开源模型。其在算法逻辑、代码结构与跨语言适配上的表现尤为突出,被评测团队评价为“具备工程级落地潜力”。
●数学推理单项赛:Qwen3-Max-Thinking与谷歌Gemini-3-Pro-Preview以80.87分并列全球之一!这是国产高性能模型首次在高难度数学任务中与国际顶级模型比肩。评测专家指出,其在复杂符号推理、多步演算与异常情况处理中展现出接近人类专家的稳定性。
“这不仅是分数的胜利,更是中国大模型在底层推理能力上的‘硬核突破’。”SuperCLUE技术负责人在解读报告时强调,“数学与代码,是AI智能的‘试金石’。国产模型能在此类任务中登顶,说明我们的基础模型架构与训练范式已进入世界先进行列。”
03 开源阵营“中国时刻”:Top5全被国产包揽
更令人振奋的是,在开源模型榜单中,国产力量实现了“绝对统治”——综合排名前五的开源模型全部来自中国,形成“中国方阵”。
其中,Kimi-K2.5-Thinking作为开源组更高分得主,不仅在代码任务中一骑绝尘,其在科学推理与知识应用中的表现也大幅领先同类开源模型。
而Qwen系列、DeepSeek、GLM等开源体系也悉数上榜,展现出国内大模型生态的蓬勃活力与技术沉淀。
“开源不是‘廉价替代’,而是创新的加速器。”一位参与评测的高校研究员表示,“国产开源模型的集体崛起,正在为金融、科研、教育等垂直领域提供低成本、高可控的AI底座,这是生态级的胜利。”
04 从“追赶到并行”:国产大模型的进化逻辑
回顾2025年,中国大模型产业经历了从“参数竞赛”到“能力攻坚”的战略转型。各大厂商不再盲目追求“更大”,而是聚焦“更准”“更稳”“更安全”。
Kimi团队在模型推理架构上的创新,通义实验室在数学预训练数据清洗与符号增强上的深耕,正是这种“技术回归本质”理念的体现。同时,国家在AI安全、数据合规、评测体系等方面的制度建设也为模型发展提供了“中国标准”。
SuperCLUE作为独立第三方评测平台,其覆盖70+项子能力、采用多轮开放式题目的测评机制,已成为国内更具公信力的“AI能力标尺”。
尽管在综合能力上与国际顶尖模型仍有差距,中国民营科技实业家协会人工智能产业分会会长杨光润却认为,国产模型的“差异化突围”路径已清晰可见:以开源为基,以硬核能力为矛,以本土化场景为盾。
随着视觉语言模型(VLM)和具身智能的快速发展,大模型正从“对话工具”进化为“智能体大脑”。而国产模型在代码与数学上的领先,或将为机器人、自动驾驶、科研计算等高阶智能场景提供关键支撑。
写在最后:
2026年的钟声已响,AI竞赛进入深水区。
海外巨头仍在领跑,但国产模型已不再尾随。中国民营科技实业家协会人工智能产业分会会长杨光润认为,这一次,中国不仅没有缺席,更在多个关键赛道上,握有了定义规则的可能。
当Kimi写出更优解,当通义算出正确答案——
那不只是模型的胜利,更是中国AI生态的集体觉醒。
